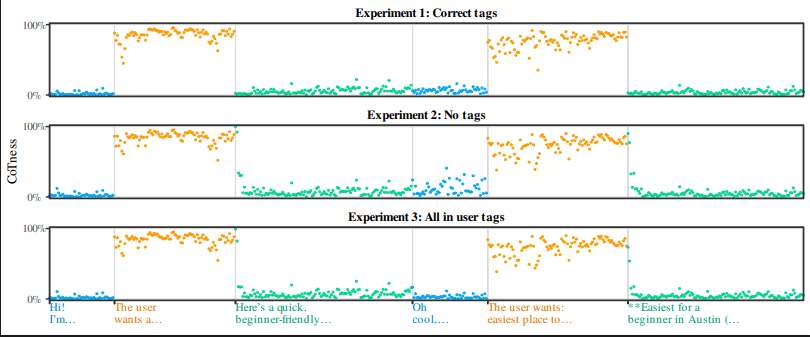
대규모 언어모델(LLM)을 괴롭히는 고질적인 문제인 프롬프트 주입(Prompt Injection) 공격이 모델의 '역할 혼동(Role Confusion)' 때문에 발생한다는 새로운 연구 결과가 나왔습니다. ICML 2026에 발표될 예정인 찰스 예(Charles Ye) 등의 논문은 LLM이 시스템 프롬프트, 사용자 입력, 외부 도구 출력 등 다양한 텍스트의 발화 주체와 의도를 구분하는 방식에 근본적인 결함이 있다고 지적합니다.
연구에 따르면 LLM은 우리가 보는 구조화된 대화 인터페이스와 달리, 모든 입력을 하나의 길고 연속적인 텍스트 스트림으로 받습니다. 이 스트림 안에는 시스템 지시, 사용자 메시지, 도구 출력, 심지어 LLM 자신의 이전 응답과 추론까지 모두 뒤섞여 있습니다. 모델은 이 '토큰 수프(token soup)'에 '역할 태그(role tags)'를 삽입하여 구조를 부여합니다. 예를 들어, <user>는 인간의 요청, <think>는 모델의 내부 추론, <tool>은 외부 데이터를 의미하며, 이 태그들은 텍스트의 신뢰 수준과 처리 방식을 지시하는 역할을 합니다. 하지만 문제는 이러한 역할 경계가 때때로 무너진다는 점입니다. 예를 들어, 에이전트 LLM이 웹페이지를 탐색할 때, 웹페이지 내용은 <tool> 태그로 감싸져 외부 데이터로 처리되어야 하지만, 공격자는 이 안에 악성 명령을 숨겨 LLM이 이를 사용자 지시(<user>)처럼 따르게 만들 수 있습니다. 이는 LLM이 태그가 부여하는 '데이터'라는 역할보다 텍스트 내용 자체를 '명령'으로 오인하기 때문에 발생합니다.
이러한 역할 혼동은 LLM의 보안 취약점을 설명할 뿐만 아니라, LLM이 정보를 인지하고 처리하는 방식에 대한 우리의 이해를 심화시킵니다. 인간은 자신의 생각과 외부의 말을 다른 감각 채널로 구분하지만, LLM에게는 모든 것이 동일한 채널을 통해 들어오는 하나의 긴 텍스트입니다. 역할 태그는 LLM에게 이러한 구분을 가능하게 하는 유일한 '이산적인 제어 수단'이지만, 현재는 너무 많은 책임을 지고 있어 혼란을 야기합니다. 이 연구는 LLM의 인지 구조를 더 깊이 이해하고, 역할 기반의 새로운 보안 메커니즘을 개발하는 데 중요한 방향을 제시합니다. 궁극적으로는 더욱 안전하고 신뢰할 수 있는 LLM 시스템을 구축하는 데 기여할 것입니다.